












本文
GPGPUを用いた超並列環境による高速計算手法の開発
山口 隆志[発表者](情報技術グループ) 、大原 衛(経営企画室)
1.はじめに
情報通信機器の発展に伴い、高密度実装が可能で高速かつ低消費電力な光配線に対する必要性が高まっている。基板上における光通信を実現するためには、光導波路の構造や特性を数値シミュレーションによって検討する必要がある。しかし、光の波長領域における解析では、対象の構造を微少な離散間隔で解析する必要があるため膨大なマシンパワーが要求される。この問題を解決する方法として、Graphics Processing Unit(GPU)の持つ並列演算性能を利用することが有効であると考えられる。本研究では、GPUを用いて高速に並列計算することが可能なアルゴリズムを検討しシミュレータの開発を行った。
2.方法
本研究ではFDTD(Finite-Difference Time-Domain)法を光の解析アルゴリズムとして用いた。また、NVIDIA社が提供しているCUDAを用いてGPU用プログラムの開発を行った。GPUを搭載するビデオカード内部の模式図を図1に示す。GPUによる高速計算を実現するため、図1の構造を考慮し、効率的なメモリレイアウトやマルチプロセッサへのスレッドの割り当て、複数GPUの同時使用について検討し実装を行った。
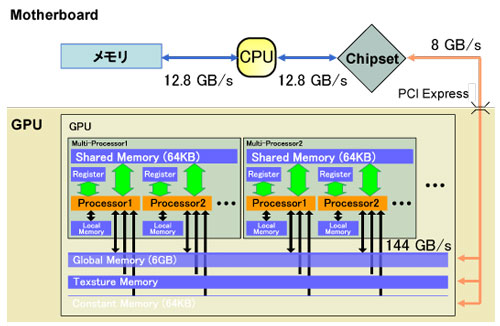
図1 ビデオカード内部構造の一例
3.結果・考察
本研究で作成したシミュレータの解析速度を評価するため、図2に示す切断されたスラブ光導波路の解析を行った。ただし、入射波長を1μm、クラッドとコアの比誘電率をそれぞれ1.0と2.2、コア幅を10μm、切断されたコア間の距離を20μmとした。Intel Core i7 930(CPU)とNVIDIA Tesla C2070(GPU)を用いた場合における解析時間の比較を図3に示す。図3より、Tesla C2070を1から3枚使用した場合、Core i7 930より解析速度がそれぞれ約22倍、約43倍、約63倍高速であることが分かる。
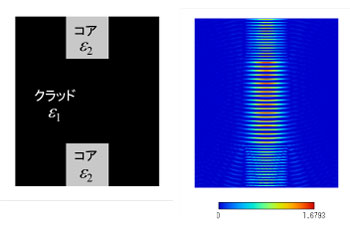
図2 光導波路の解析例
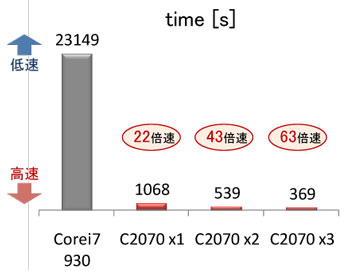
図3 解析速度の比較
4.まとめ
光配線の実現に向けた数値シミュレーションを行うため、GPUを用いた高速シミュレータを開発した。解析例から、本研究で作成したシミュレータが従来よりも高速に解析できることを示した。